ScalaQuest PPS Report
1 Introduzione
L’obiettivo di questo progetto è quello di realizzare un framework per permettere l’implementazione di giochi del genere Interactive Fiction (come ad esempio Zork), nei quali il giocatore può utilizzare comandi di testo per influenzare l’ambiente e proseguire nel gioco.
Il progetto dovrà in primis fornire una libreria, tale da permettere la creazione di storie giocabili da utenti terzi, tramite un API facilmente accessibile.
Dovrà inoltre fornire una piattaforma per l’esecuzione delle storie, basata su un’interfaccia da linea di comando. Questa permetterà ad utenti terzi di interagire con le storie create precedentemente, modificando lo stato nel gioco e avanzando man mano nella storia.
Il progetto è stato ideato per essere oggetto di esame in maniera mutuata per i corsi di PPS e LSS. A tale scopo, fin dalla definizione delle fondamenta del progetto si è posta particolare attenzione nell’adozione di una metodologia tale da integrare le peculiarità di entrambi i corsi. Il report di LSS descrive estensivamente gli aspetti relativi allo stesso corso, tra cui:
- Il processo di sviluppo e di design, incentrato su un approccio di tipo Domain Driven;
- Le pratiche DevOps poste in atto.
Il report di LSS va considerato parte integrante della documentazione di progetto, e approfondisce alcuni aspetti non trattatti all’interno del report corrente. Si consiglia quindi di consultare anche quest’ultimo.
Nel report corrente vengono invece approfonditi nel dettaglio gli aspetti inerenti al corso di Paradigmi di Programmazione e Sviluppo.
1.1 Sorgenti
Il report corrente tratta il processo di sviluppo con particolare focus sul repository scalaquest/PPS-19-ScalaQuest. Ad ogni modo, i sorgenti di progetto consistono nell’insieme di repository GitHub parte dell’organizzazione ScalaQuest.
Tutti i sorgenti sono resi disponibile sotto licenza MIT, in quanto chiara, breve e concisa. Non vengono poste particolari limitazioni riguardo la consultazione e il riuso da parte di terzi del software fornito.
Ulteriori informazioni, documentazione e guide possono essere reperite a partire dal sito di progetto.
2 Processo di sviluppo adottato
Il processo di sviluppo adottato rispecchia i principi della metodologia Scrum, basata su un approccio di tipo Agile, con integrazioni nella fase iniziale legate a un approccio di tipo DDD.
La metodologia Scrum richiede l’assegnamento di specifici ruoli, che sono stati distribuiti tra i componenti come di seguito specificato:
A Filippo Nardini è stato assegnato il ruolo di Product Owner: responsabile per la massimizzazione del valore del progetto, in linea teorica dovrebbe esprimere i requisiti del cliente. Nel nostro caso, non avendo un vero e proprio committente, è stato assegnato lui il ruolo in quanto l’idea di fondo è stata proposta e delineata dallo stesso;
A Riccardo Maldini è stato assegnato il ruolo di Scrum Master. Il suo ruolo è quello di facilitare il lavoro di Project Owner e team, innalzandosi a garante dei principi Scrum, e nel delineare l’organizzazione di Sprint e meeting;
A tutti i componenti è stato assegnato il ruolo di team di sviluppo. Scrum prevede che i ruoli di Project Owner e Scrum Master non debbano in linea di massima sovrapporsi con il team di sviluppo; è stata però di fatto una scelta obbligata, visto le dimensioni ridotte del team.
Il lavoro è stato suddiviso in Sprint settimanali, ad eccezione delle primissime iterazioni che hanno richiesto del tempo aggiuntivo.
2.1 Strumenti a supporto di Scrum
2.1.1 GitHub Projects
Si è tenuto traccia del Backlog di progetto grazie allo strumento GitHub Projects. Questo rappresenta di fatto una versione di Trello interna a GitHub, che ne eredita la maggior parte delle caratteristiche (ad esempio, l’organizzazione dei task in liste), aggiungendo ad esso però importanti integrazioni con GitHub. È possibile ad esempio associare Issue e Pull Request direttamente ai task, automatizzarne e sincronizzarne apertura e chiusura con gli stessi. È possibile accedere alla backlog di progetto, essendo pubblica, a questo indirizzo.
2.1.2 Scrum Overview Document
Si è tenuto traccia dei meeting settimanali e dei progressi grazie alla redazione di un documento denominato Scrum Overview, aggiornato dopo ogni meeting, accessibile a questo indirizzo.
2.1.3 GitHub Issues e Pull Request
Per approfondire e delineare l’effettiva interazione e evoluzione del progetto, sono stati utilizzati estensivamente Issue e Pull Request di GitHub. Consultando le stesse, è possibile ricostruire interamente il processo di sviluppo. Un “indice” dal quale recuperare i principali Issue e PR è contenuto all’interno del sopracitato documento di Scrum Overview (sec. 2.1.2).
2.1.4 Discord
Si è utilizzato il software Discord per effettuare i meeting settimanali e quotidiani. Si è preferito questo strumento, rispetto ad altri simili quali Slack, Microsoft Teams, Google Meet o altri, per vari motivi:
- per la buona qualità di video-chiamata;
- per la possibilità di lavorare in stanze differenti in contemporanea, e passare agevolmente da una stanza all’altra;
- per la possibilità di implementare hook integrati con GitHub, tali per cui ogni modifica alle repository di progetto viene notificata a tutti i componenti del gruppo, tramite un apposito canale.
2.1.5 Miro
Oltre agli strumenti citati, nella fase iniziale si è sfruttato estensivamente anche un tool denominato Miro. Esso consiste di fatto in una board collaborativa, che ci ha permesso di generare sketch analizzare i casi d’uso, effettuare sedute di knoledge chrunching. La board, pubblicamente accessibile, può essere consultata da questo link.
2.2 Meeting e interazioni pianificate
2.2.1 Meeting settimanali
Ad ogni fine settimana è stato portato avanti il meeting settimanale, durante il quale si sono effettuate le operazioni di Sprint Review, Retrospective e Planning. Nella pratica, tali meeting hanno seguito la seguente scaletta:
Retrospettiva: ogni componente ha aggiornato i colleghi riguardo ciò che è stato fatto durante lo Sprint precedente. Questo ha portato spesso a importanti discussioni su tematiche emerse dal lavoro di ogni membro del team.
Sincronizzazione del lavoro effettuato: gran parte del lavoro è stato effettuato in branch separati (feature branch); grazie a una buona organizzazione, difficilmente il lavoro di un sotto-team è entrato in conflitto con quello di un altro. Ad ogni modo, tipicamente, al termine dello Sprint si è andati a chiudere le varie pull request aperte, gestendone eventuali conflitti minori.
Definizione dei task dello Sprint successivo e aggiornamento del backlog: a questo punto del meeting si vanno a definire gli obiettivi della settimana a venire, andando ad aggiornare di conseguenza il Backlog, trasferendo inoltre i task completati nello Sprint corrente nella colonna dei task completati negli Sprint precedenti. In questa fase si vanno inoltre a definire gli obiettivi prioritari, spostandoli nella colonna di Backlog dello Sprint corrente.
Assegnamento dei task: i task individuati vengono quindi assegnati ai componenti del team, o ad eventuali team interni (sec. 2.3).
2.2.2 Meeting di aggiornamento periodici
Ogni due o tre giorni è stato effettuato un meeting di aggiornamento tra tutti i componenti del team. Per ragioni pratiche, non è stato possibile eseguire Daily Scrum giornalieri, sostituiti però da questi meeting a cadenza più flessibile. Al pari del Daily Scrum, durante questi meeting ci si è aggiornati riguardo i progressi attuati nei singoli team interni.
Sulla base di questi meeting, si sono anche prese eventuali misure di revisione in itinere dei task: è ad esempio successo che in alcuni casi un sotto-team completasse tutti i task ad esso assegnati in anticipo, o che in alcuni altri casi ci si rendesse conto che il task sarebbe stato concluso nello Sprint successivo. In questi casi, si è aggiornato di conseguenza il Backlog.
2.3 Organizzazione in team interni
Il lavoro è stato sviluppato principalmente in team interni composti da due o tre componenti, seguendo la metodologia pair programming. Questa modalità, già utilizzata in altri progetti, pur portando iniziali rallentamenti dovuti a una minore parallelizzazione, porta ad un innalzamento della qualità del prodotto, e ad un minore debito tecnico, in quanto le scelte vengono discusse e revisionate in tempo reale dagli stessi membri del team. Essa porta inoltre i diversi componenti a comprendere meglio la parte sviluppata, e responsabilizza i singoli, dovendo a rotazione prendere il comando del team.
In particolare:
- Si è individuato un sotto-team 1, composto dai componenti Riccardo Maldini, Jacopo Corina e Thomas Angelini. Tale team è stato responsabile in particolare di aspetti relativi alla definizione del componente model (approfondito in seguito);
- Si è individuato un sotto-team 2, composto dai componenti Filippo Nardini e Francesco Gorini. Il team ha approfondito i concetti legati al parsing del testo, e all’interpretazione dello stesso tramite l’engine Prolog;
- Task d’importanza chiave sono stati portati avanti in comune tra tutti i componenti;
- Task minori sono stati portati avanti singolarmente da componenti del team.
2.4 Strategie di Version Control
Durante lo sviluppo del progetto, non si è adottato sempre lo stesso modello di sviluppo. Nelle prime fasi, durante le quali non si aveva del codice abbastanza stabile da essere “rilasciabile”, si è seguito un approccio più flessibile e prototipale, denominato GitHubFlow, per poi evolvere il modello ad un più strutturato GitFlow.
Questi aspetti, congiuntamente con ciò che viene riportato riguardo i flussi di CI/QA e CD, sono stati approfonditi nel dettaglio nel report di LSS. Si rimanda quindi a tale report per una panoramica più completa.
2.4.1 GitHub Flow in fase embrionale
GitHub Flow è un modello di sviluppo ispirato a GitFlow, ma con alcune caratteristiche che lo rendono più flessibile e semplice da porre in atto.
Il modello richiede ad esempio che la versione stabile del software sia mantenuta su un branch main (o master), senza però la necessità di un branch dev parallelo. Allo stesso tempo, però, GitHub Flow suggerisce di organizzare il lavoro in feature/* branch, come in GitFlow, i quali confluiscono nel main.
Alla luce di ciò, le prime iterazioni di progetto hanno presentato particolare flessibilità sulle modalità di modifica del codice. Le varie feature sono state sviluppate sui rispettivi feature/* branch, poi riversati nel main tramite pull request. Si è subordinato la chiusura di queste alla revisione da parte di un membro del team (solitamente, non appartenente allo stesso sub-team, così da aggiornare l’altro team sui progressi di progetto) e al passaggio di determitati workflow di CI e QA.
Unica deroga a questo flusso di lavoro, è stata posta per modifiche minori, tali da non impattare sul funzionamento generale del codice (es. correzione di typo). Per queste è stato permesso il push diretto sul branch main.
2.4.2 GitFlow a regime
Una volta predisposta una codebase sufficientemente stabile, e una volta abilitati i workflow di Continuous Delivery, si è migrato a un più strutturato modello GitFlow. Questo permette di avere nel branch main la versione ufficiale e stabile, sempre associata a una release. A ogni push nel main deve corrispondere un tag annotato, associato a sua volta a un numero di versione. La versione “di lavoro” del codice, parziale ma potenzialmente rilasciabile, risiede nel branch dev.
I vari feature/* branch confluiscono ora tramite pull request in dev, con gli stessi vincoli formulati per modello precedente (controlli di CI obbligatori e revisione di un utente obbligatoria), e la stessa deroga per le modifiche minori. In aggiunta, per una maggiore leggibilità e organizzazione del codice, si è adottata una precisa politica di merge, che prevede che queste pull request vengano chiuse tramite squash and merge, con un breve commento nel commit che ne identifichi il changelog.
Il main viene aggiornato tramite delle pull request sullo stesso originate da branch release/X.Y.Z (o hotfix/X.Y.Z), originati a loro volta dal dev; con X.Y.Z si intende un numero di versione, formulato secondo le regole del semantic versioning. Queste pull request presentano, oltre ai vincoli di validazione visti per le precedenti (controlli di CI e revisione di un membro del team obbligatoria), anche la necessità di presentare una coverage superiore al 75% nei moduli Core e CLI. Sono poi presenti degli accorgimenti ulteriori per la delivery automatizzata degli asset, e la gestione dei tag, indicati in sec. 6. Infine, una politica di merge ben precisa è adottata alla chiusura di queste pull request, le quali richiedono un merge commit che riporti, come commento del commit, un breve changelog1.
2.5 Strumenti di test, build e CI
Il progetto sfrutta Gradle come build automation tool. La scelta è dovuta primo luogo in quanto richiesto per l’integrazione con il corso di LSS. Ciò è comunque risultato molto utile per organizzare la build in maniera più strutturata, e per approfondirne gli strumenti di integrazione con Scala. A tal proposito, il codice è organizzato in più sotto-progetti, individuati a seguito di un’iniziale sessione di Domain Driven Design.
È stato adottato per il testing del codice Scala il framework ScalaTest. Si è inoltre sperimentato WordSpec come stile di test. ZIO Test è stata utilizzata per il testing del framework funzionale ZIO.
2.5.1 Continuous Integration e Quality Assurance
Particolare attenzione è stata posta nell’individuazione di misure per assicurare la qualità del codice. Sono stati predisposti dei workflow a garanzia di Continuous Integration e Quality Assurance, costruiti con il tool GitHub Actions. Sono stati posti criteri di qualità man mano più stringenti e vincolanti, a seconda del grado di stabilità del branch. In generale, main e dev non possono essere modificati senza che il codice passi tutti i controlli di CI/QA, e senza che la pull request venga prima revisionata da un ulteriore componente del team. Per il branch dev non è necessaria la revisione di un ulteriore membro, ma rimangono validi i controlli di CI/QA.
In primo luogo, ogni push o pull request genera un controllo tramite il tool esterno SonarCloud, il quale definisce soglie qualitative basate su coverage, mantenibilità, code smells, presenza di bug conosciuti e molto altro. Sono presenti inoltre ulteriori controlli basati su workflow CI/QA custom, nei quali viene effettuato il lint-styling del codice tramite il plugin spotless, poste ulteriori soglie di coverage, effettuati test ed effettuata la build del codice su molteplici piattaforme.
2.5.2 Automazione della delivery
Sono state inoltre predisposte dei workflow per il deploy e il delivery delle release, strutturate in maniera tale da rispettare i requisiti imposti da GitFlow, apportandone importanti caratteristiche di automazione.
Nel momento in cui si desideri generare una release, il nostro flusso di lavoro GitFlow-based prevede che venga generato un branch release/X.Y.Z, e che venga aperta una pull request su main a partire da questa. Quanto detto è l’unica operazione manuale da effettuare: una volta chiusa la pull request, revisionata la stessa e passati i controlli di CI, un workflow genera il tag annotato della versione, inferendolo dal nome del branch. Vengono quindi generati gli asset collegati alla release, e resi disponibili sia nella sezione Release di GitHub del progetto, che sulla repository pubblica Maven Central (modulo core e modulo cli). Vengono inoltre generati ScalaDoc, report di coverage e di test, resi disponibili all’interno dello spazio web GH Pages associato al progetto.
Un meccanismo equivalente è stato sviluppato per la repository che ospita le relazioni di progetto. Al momento della release, vengono generate le relazioni (a partire da codice Markdown) in formato PDF LaTeX e HTML (pps report, lss report, appendix), tramite il tool Pandoc.
3 Requisiti
I requisiti sono stati individuati a seguito di diverse sessioni di knowledge crunching, nelle primissime iterazioni di progetto. Queste sono state portate avanti congiuntamente da tutti i componenti del team, con lo scopo di definire glossario, elementi di modellazione di base e le loro interazioni.
In linea di massima, durante le sessioni i requisiti sono andati delineandosi, grazie al confronto tra la visione di base proposta dal Product Owner e le proposte costruttive dei vari membri del team. Partendo dai concetti individuati si sono andate a creare le entità alla base per l’implementazione concreta di progetto.
Si è data molta importanza a tale fase iniziale, tanto da portarla avanti per quasi due iterazioni complete di Sprint. Ciò allo scopo di creare dei requisiti il più possibile stabili. A seguire, sono stati elencati i requisiti individuati.
3.1 Requisiti di business
Per requisiti di business si intendono i requisiti che delineano la base del progetto:
Il progetto consiste in un framework utilizzabile da sviluppatori terzi (storyteller, nel nostro glossario) per creare giochi di tipo Interactive Fiction;
L’utilizzatore del gioco (user, nel nostro glossario) esprime i comandi attraverso delle frasi in linguaggio naturale. Ciò rende necessaria un’interpretazione lessicale e sintattica delle stesse;
Il gioco è strutturato in iterazioni successive: ogni comando inserito dallo user modifica lo stato corrente del gioco, generando un output che lo descrive; sulla base di questo lo user prende una decisione su quale sarà il comando successivo.
3.2 Requisiti utente
Per requisiti utente si intendono i requisiti che l’utente si aspetta dal sistema. Le categorie di utenti target del sistema sono due, ognuna con i propri requisiti caratteristici.
3.2.1 Storyteller
Il termine storyteller identifica i soggetti che utilizzano il sistema per la creazione di giochi. Sono date a lui le seguenti possibilità:
Utilizzare un’API minimale ma completa per la generazione di giochi di genere Interactive Fiction, accessibile tramite un linguaggio di programmazione idoneo;
Modellare la propria storia, e i componenti che la caratterizzano;
Definire dei comportamenti associati a tali componenti, intesi come delle funzioni in grado di modificare lo stato del gioco e l’output mostrato allo user;
Definire le parole chiave (come nomi e verbi) che lo user può utilizzare, combinati in frasi anche complesse, per dettare comandi al motore di gioco.
3.2.2 User
Il termine user identifica i soggetti che utilizzano giochi creati tramite il framework. Tale soggetto va considerato nell’analisi dei requisiti utente al pari dello storyteller, in quanto esso rappresenta sia un utente indiretto (essendo il fruitore di storie create dallo storyteller) che diretto (dovendo il sistema includere degli esempi di utilizzo). Sono date lui le seguenti possibilità:
- Interagire con le storie generate dagli storyteller, tramite un’interfaccia grafica a linea di comando; questa deve supportare l’input di frasi in linguaggio naturale, e fornirne un output testuale in risposta.
3.3 Requisiti funzionali
Per requisiti funzionali si intendono le funzionalità che caratterizzano il progetto:
Fornire un modello sul quale rendere possibile la costruzione di storie di tipo Interactive Fiction;
Fornire una piattaforma sulla quale lanciare le storie, agente da linea di comando;
Fornire la possibilità di creare piattaforme anche differenti da quella standard (ad esempio da interfaccia web);
Fornire un engine Prolog in grado d’interpretare semplici comandi in linguaggio naturale in lingua inglese, mappandoli in azioni applicabili sulla storia;
Fornire dei costrutti comuni per la definizione della storia, già modellati e potenzialmente riutilizzabili, al fine di rendere più agevole il compito dello storyteller;
Esporre un set di esempi, utili come spunto di partenza per la creazione, da parte dello storyteller, della propria storia giocabile.
3.4 Requisiti non funzionali
Per requisiti non funzionali si intendono caratteristiche del progetto utili a minimizzare le problematiche d’integrazione tra le varie componenti del framework, verificarne i comportamenti e garantire uno stile di scrittura conforme alle convenzioni adottate:
Effettuare test per verificare il comportamento del codice, ponendo particolare attenzione ai componenti core;
Introdurre pratiche DevOps, volte ad automatizzare la verifica del codice, porre forti condizioni di QA, compilare il codice ed eseguire i test su differenti sistemi operativi, e adottare workflow di Continuous Delivery;
Seguire la metodologia Agile Scrum, cercando di restare più fedeli possibile al principio originale, definendo ruoli e Sprint settimanali al fine di raggiungere una corretta organizzazione temporale.
3.5 Requisiti d’implementazione
Per requisiti d’implementazione si intendono tutte le tecnologie e le soluzioni d’implementazione considerate imprescindibili nella realizzazione del progetto.
Applicare il paradigma di programmazione funzionale;
Utilizzare il linguaggio di programmazione Scala, con garanzia di compatibilità sulla versione 2.13 (Java 11);
Utilizzare il sistema di build automation Gradle;
Utilizzare GitHub come servizio di repository per il progetto;
Utilizzare GitHub Actions per CI e CD;
Utilizzare ScalaTest, ZIO Test e WordSpec come specifica di test;
Utilizzare il linguaggio Prolog per implementare l’engine.
4 Design architetturale
Il gioco si struttura dal punto di vista dello user in diverse iterazioni, per ognuna delle quali viene intercettato l’input utente (in linguaggio naturale), e a seguito di varie elaborazioni viene restituita una risposta (in formato testuale, o in altri formati).
Risulta quindi naturale implementare ogni iterazione come una funzione, che dato un comando testuale e lo stato del gioco, restituisce lo stato modificato e l’output per l’utente. Faremo riferimento a questa funzione con il nome di pipeline, essendo di fatto strutturata come una vera e propria “catena di montaggio”, come verrà in seguito descritto.
L’architettura di progetto si fonda tutto attorno a questa funzione. Sarà di fatto necessario un modulo incaricato di prendere un comando utente e restituirne l’output, e un modulo incaricato d’iterare la stessa, tale da comporre una sessione di gioco completa.
Parallelamente alla gestione della pipeline, dovrà essere resa disponibile un’API per lo storyteller, così da permettere a lui di creare nuove storie basate su questo modello.
4.1 Architettura di massima
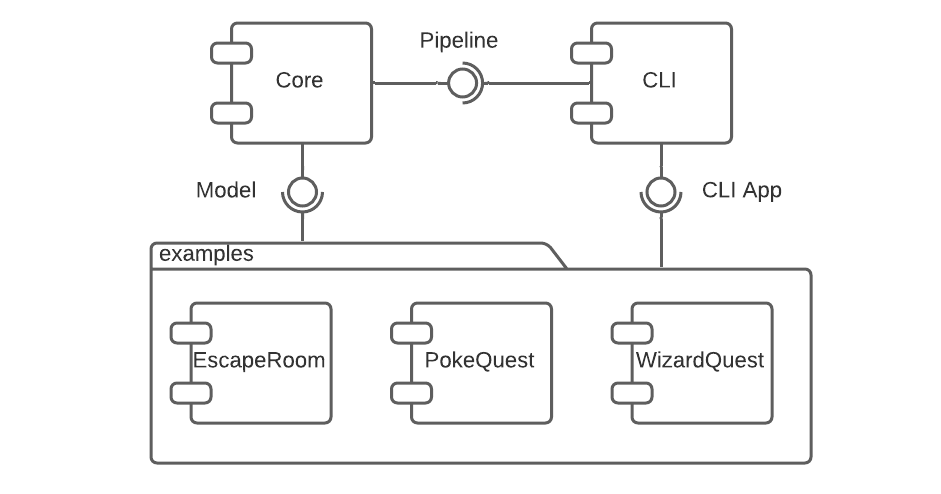
Si è organizzato quindi il sistema in più macro-componenti, corrispondente ognuno a un sotto-progetto Gradle separato. Le loro relazioni sono riportate tramite il diagramma dei componenti a fig. 4.1. Sono stati individuati:
Il modulo Core, che implementa l’engine di gioco, la pipeline, e il necessario per rendere possibile modellare nuove storie;
Il modulo CLI, che fornisce un’implementazione in grado di eseguire sessioni di gioco basate su Command Line Interface. Il modulo include Core come dipendenza, rappresentando da solo la libreria necessaria per generare storie interagibili a linea di comando;
I moduli Examples, che rappresentano dei giochi di esempio, andando a mostrare le modalità consigliate per l’utilizzo di CLI nell’implementazione di storie.
In seguito si vanno ad approfondire le caratteristiche dei singoli moduli.
4.1.1 Core
Il modulo Core rappresenta l’elemento centrale del sistema, tale da implementare l’engine di gioco, la pipeline, e il necessario per rendere possibile modellare nuove storie. È strutturato ad alto livello in molteplici sezioni, corrispondenti in linea di massima a package separati:
Model: contiene tutti i componenti e gli strumenti necessari a modellare una storia;
Parsing: contiene le logiche alla base della fase di parsing della pipeline, ovvero ciò che concerne l’interpretazione dell’input testuale dell’utente tramite l’interprete Prolog.
Application: comprendono delle utility per dare un “template” di base alle storie, facilitandone la costruzione, e la generazione delle regole grammaticali Prolog utili alla fase di parsing;
Dictionary: contiene tutti gli elementi che definiscono il vocabolario utilizzato dal giocatore all’interno di una storia. In particolare è composto da un insieme di oggetti e un insieme di verbi;
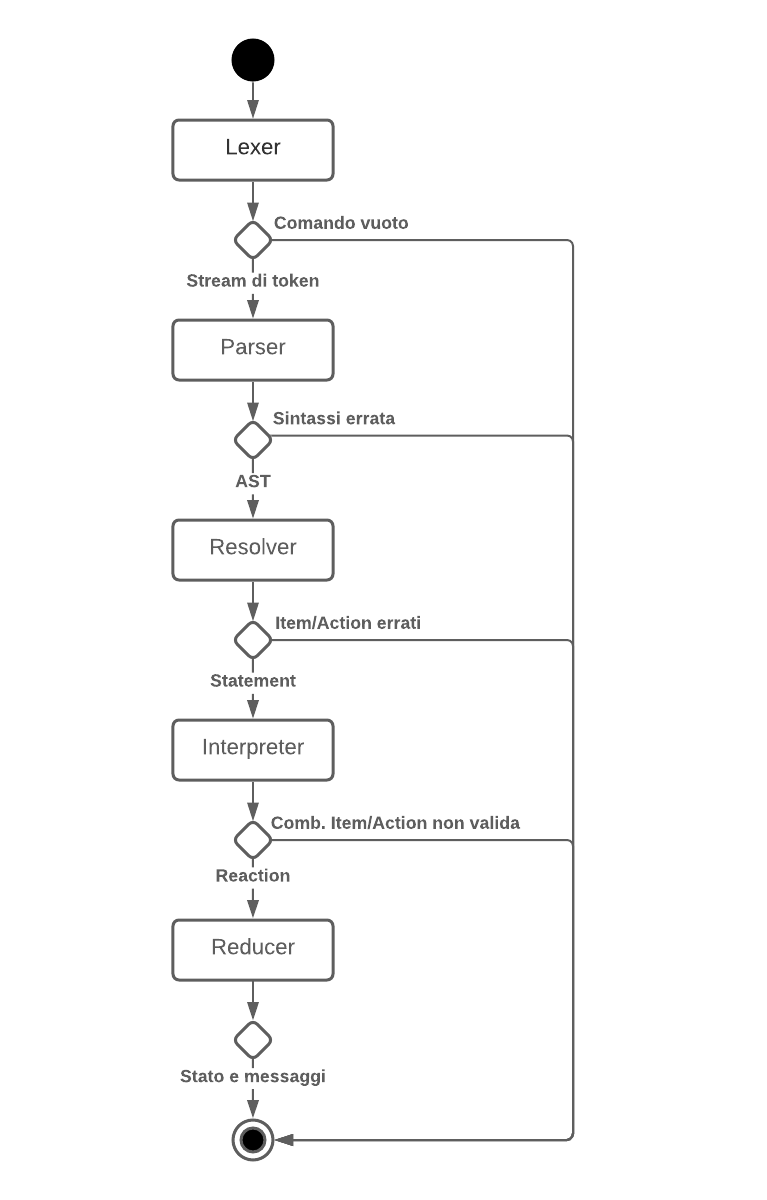
Pipeline: definisce l’elaborazione di una singola iterazione di gioco, dall’input di un comando testuale e dello stato del gioco, all’output dello stato stesso modificato e del contenuto visualizzato dall’utente. L’elaborazione si struttura in differenti fasi, rappresentate in fig. 4.2. Ogni fase è a sua volta contenuta in un package differente:
Lexer: dato l’input dello user, lo si sottopone ad un’analisi lessicale, volta alla creazione di uno stream di token. Ogni token corrisponde ad una parola, distinta in base alla separazione tramite spazi;
Parser: dato il risultato del
Lexer, lo si sottopone ad un’analisi sintattica tramite l’interprete Prolog, dalla quale viene generato un Abstract Syntax Tree;Resolver: dato il risultato del
Parser, si associa ad ogni suo elemento un significato, producendo unoStatement, ossia un comando comprensibile dal modello;Interpreter: dato il risultato del
Resolver, si verifica che sia possibile applicare loStatementsullo stato corrente del gioco. Quando possibile, viene generata una Reaction ossia una funzione contenente le eventuali modifiche da applicare sullo stesso, e tale da tener traccia dell’output da mostrare all’utente;Reducer: data la
Reactionottenuta al termine del passo precedente, si provvede ad applicarla allo stato corrente del gioco, aggiornandolo e generando eventuali messaggi utili per l’interazione con lo user.
4.1.2 CLI
Il modulo CLI fornisce un’implementazione in grado di eseguire sessioni di gioco basate su Command Line Interface. Il modulo include Core come dipendenza, rappresentando da solo la libreria necessaria per generare storie a linea di comando.
L’implementazione fornita itera di fatto l’esecuzione della pipeline. È possibile individuare, per ogni iterazione, le seguenti fasi:
- Viene letta la frase inserita dallo user;
- Viene messa in azione la pipeline che restituisce un risultato;
- Viene creato il messaggio di risposta in base a ciò che restituisce la pipeline;
- Viene stampato a video il messaggio di risposta;
- Se il gioco è terminato, viene chiusa la sessione, altrimenti si ricomincia il ciclo.
4.1.3 Examples
Sono state incluse all’interno del progetto diverse storie di esempio, generate tramite l’utilizzo del modulo CLI:
EscapeRoom: lo user si trova all’interno di uno scantinato con vari oggetti coi quali è concessa l’interazione. La storia si focalizza sull’utilizzo di vari builder preimpostati per la generazione della stessa;
PokeQuest: lo user viene catapultato nel mondo Pokemon. La storia mostra come sia possibile generare dei componenti completamente custom, limitando l’utilizzo di builder;
WizardQuest: lo user si ritrova nei panni di Harry Potter all’interno della Camera dei Segreti. La storia mostra come sia agevole spostare oggetti tra le varie stanze.
4.2 Pattern architetturali
La gestione dello stato all’interno del progetto si ispira al pattern architetturale Flux.
Il flusso di dati di questa applicazione segue un percorso unidirezionale ciclico. Quest’ultima soluzione in particolare, risulta essere molto efficace con il problema definito in questo progetto in quanto ad ogni input generato dallo user viene aggiornato lo stato. Il prossimo input utente viene valutato a partire dal nuovo stato attuale.
In questo paradigma viene considerato come punto centrale il nodo Dispatcher, attraverso il quale fluiscono tutti i flussi di dati. Nel nostro caso questo concetto è stato esploso ed è stato implementato attraverso la creazione della pipeline.
4.3 Scelte tecnologiche
Al fine di rispettare i requisiti proposti, sono state effettuate delle scelte su alcune tecnologie che hanno influenzato poi anche in maniera importante alcune scelte architetturali.
4.3.1 TuProlog
TuProlog rappresenta la libreria scelta per quanto concerne la creazione del motore Prolog di Natural Language Processing. Si è scelta questa libreria per avere una solida base per la fase di parsing.
Le motivazioni per cui è stata scelta sono molteplici:
perfetta integrazione tra tuProlog e il mondo JVM e questo ha consentito di utilizzare Prolog all’interno del linguaggio Scala senza particolari problematiche dovute all’integrazione di API diverse;
possibilità di utilizzare la grammatica Prolog DCG importando una piccola parte aggiuntiva alla libreria.
Tra i possibili svantaggi derivanti dall’utilizzo della libreria tuProlog vi potrebbe essere un problema legato alle prestazioni. Essendo sviluppata in Java e quindi su JVM, potrebbero non essere ottimizzati i tempi attraverso i quali vengono esplorate le soluzioni Prolog.
Tuttavia nel nostro progetto il Prolog non viene richiamato in maniera intensiva, ma il suo utilizzo si limita alla parte della pipeline che esegue l’analisi sintattica della frase inserita dal player. Per questo motivo, non sussistono problemi di prestazione legati alla libreria utilizzata.
4.3.2 ZIO
Per quanto riguarda la gestione di side effect e azioni asincrone si è scelto di utilizzare ZIO, una libreria che fornisce costrutti per la manipolazione di effetti utilizzando un approccio funzionale, in maniera type-safe, quindi facilmente componibili e testabili.
Il nucleo di ZIO è definito dal tipo ZIO[R, E, A], nel quale:
Rrappresenta l’ambiente necessario affinché l’effetto possa essere eseguito;Erappresenta il tipo dell’errore che la computazione potrebbe causare;Arappresenta il tipo di ritorno nel caso in cui l’effetto vada a buon fine.
Il tutto può essere visto come una versione con side-effect di una funzione R => Either[E, A].
4.3.3 Monocle Lens
Al fine di leggere e trasformare oggetti immutabili si è scelto di utilizzare la libreria Monocle, in particolare il costrutto Lens, il quale mette a disposizione un’API semplice e componibile per modificare oggetti anche innestati, senza dover ricorrere all’uso del metodo copy. La libreria fornisce una macro GenLens, che consente la creazione di Lens a partire da una case class, rendendo questa fase molto semplice.
L’uso di questi costrutti è risultato molto utile soprattutto nelle modifiche a strutture quali State e Room.
4.3.4 Cats
Durante la fase di analisi è emersa la necessità di accordarsi su quale implementazione di type classes utilizzare nel caso in cui si volessero scrivere algoritmi o strutture dati utilizzando un approccio funzionale.
È stato deciso di utilizzare Cats, in quanto mette a disposizione un insieme di astrazioni, ispirate alla teoria delle categorie, che permettono di sfruttare al massimo le caratteristiche della programmazione funzionale. La scelta di Cats piuttosto che Scalaz è stata dettata principalmente dal fatto che la prima è una libreria più nuova, che in poco tempo è riuscita a guadagnare molta popolarità nella comunità di Scala (4.2k stars su GitHub per Cats alla sua release 2.4.2 contro 4.4k per Scalaz alla sua release 7.3.3), in quanto per i casi d’uso delineati durante la fase di analisi le due sarebbero equivalenti.
Per curiosità e interesse è stata approfondita la conoscenza di questa libreria, portando a notevoli miglioramenti nella qualità del codice. Nelle fasi avanzate dello sviluppo sono state riscritte attraverso le astrazioni fornite da Cats (quali Foldable, Monoid, ecc.) sezioni del software che inizialmente non erano state progettate con i concetti di componibilità e riusabilità.
5 Design di dettaglio
5.1 Riconoscimento dei comandi testuali
In queste sezioni si descrivono le modalità con le quali Prolog è stato utilizzato nell’implementazione dei componenti atti ad interpretare i comandi dell’utente in forma testuale, associoando agli stessi un signigicato comprensibile dal modello.
5.1.1 Manipolazione di espressioni Prolog
Un problema evidente che è emerso durante la fase di prototipazione del progetto è stato quello della manipolazione delle espressioni Prolog, che all’interno del modulo del Parser è pervasivo. È stato fatto un primo tentativo di rappresentazione delle espressioni tramite l’uso di semplici stringhe, ma questa modalità si è rivelata presto inadatta e scomoda. Date le caratteristiche di Scala, si è pensato di implementare una libreria integrata all’interno del progetto, chiamata Scalog. Questa consente agevolmente di creare espressioni Prolog indipendenti dalla specifica implementazione del linguaggio, utilizzando un DSL intuitivo, i cui simboli sono ispirati direttamente a quelli del linguaggio Prolog, cercando di imitare il più possibile la sintassi originale. Inoltre, la libreria consente di effettuare pattern matching contro espressioni esistenti, in modo da agevolare il processo dell’interazione con i risultati del Parser.
5.1.2 Prolog parser
Un ideale che è stato perseguito durante lo sviluppo di tutto il software è stato quello della realizzazione di componenti riusabili. Per questo motivo si è cercato di astrarre, quando possibile, dalle specifiche implementazioni e di descrivere interfacce attraverso le quali rappresentare le realizzazioni concrete. Per il componente Parser sono state realizzate quindi delle interfacce volte a rappresentare componenti generici. In particolare:
Libraryrappresenta una generica libreria Prolog;Theoryrappresenta una generica teoria Prolog;Enginerappresenta un generico motore Prolog, il quale, inizializzato con una teoria e un insieme di librerie, è in grado di rispondere a interrogazioni.
Per comunicare con Engine si è scelto di utilizzare Scalog, in quanto agnostico a specifiche implementazioni e facilmente mappabile a costrutti di altre librerie Prolog.
A questo punto, ancor prima di realizzare un’implementazione dello specifico Engine, è già stato possibile realizzare il PrologParser: un parser che utilizza un generico motore Prolog per effettuare l’analisi sintattica di una sequenza di token.
5.2 Application structure
Giunti alla definizione degli esempi, si è rilevata la necessità di un refactoring della struttura del software. Ogni volta che si è andati ad instanziare una nuova storia, infatti, era necessario scrivere diverso codice “boilerplate”, comune a tutti gli esempi. Principalmente per quanto concerne la creazione della pipeline e del dizionario della storia, in mancanza di particolari necessità, avvengono sempre allo stesso modo. Per questo motivo si è deciso di effettuare quanto più possibile il refactoring degli elementi comuni, inserendoli all’interno del package application, all’interno del modulo core. Tale package fornisce un insieme di costrutti che consentono con poche istruzioni aggiuntive di creare una storia. All’interno di questo son confluite anche delle implementazioni di default, volte ad aumentare maggiormente l’efficienza nella scrittura della singola storia.
Son stati aggiunti anche metodi di utility, particolarmente importanti per fornire delle funzionalità adatte ad ogni storia.
In definitiva, tale processo di refactoring ha portato:
- maggiore modularità tra i componenti;
- eliminazione di codice ripetuto in tutti gli esempi;
- minore possibilità di errore per lo storyteller;
- maggiore velocità nel definire nuove storie.
5.3 Generator e GeneratorK
Tra i principali obiettivi preposti, vi è sicuramente quello di definire una sola volta gli elementi che compongono il dizionario di una storia e, a partire da questo, generare tutte le strutture dati necessarie ai componenti della Pipeline. In particolare si è reso necessario generare clausole Prolog utili al parser per svolgere l’analisi sintattica, e una struttura dati in grado di mappare in maniera biunivoca il nome di un elemento con il riferimento all’oggetto che lo descrive.
Questa necessità di generare strutture dati diverse, utilizzando un isomorfismo, a partire da un elemento A che può essere Item o Verb, si è rivelata essere un pattern fattorizzabile in un concetto più astratto e riusabile che è stato chiamato Generator[A, B], realizzato tramite una type class. Si tratta di un wrapper di una funzione A => B.
Nel dizionario, però, gli elementi sono contenuti all’interno di una collezione. Si è quindi introdotto il concetto di GeneratorK[F[_], A, B], che rappresenta un wrapper di una funzione F[A] => B, quindi una funzione in cui A è all’interno di un contesto F[_]. La scelta del nome è stata ispirata dai nomi utilizzati dalle type class di Cats, le quali presentano una lettera K nelle versioni delle type class che operano sugli higher-kinded types.
Tramite l’uso di queste due astrazioni combinate è possibile fattorizzare funzioni come List[A] => List[B] o List[A] => Map[K, V] in un’implementazione comune.
5.4 Il modello
Uno dei requisiti centrali alla base del progetto è quello di fornire allo storyteller un’API che lo aiuti a creare le proprie storie. In quest’ottica, il package model del modulo core contiene tutti i componenti utili alla creazione di una storia. Più precisamente, il modello può essere definito come l’insieme di tutti e soli componenti utilizzabili dallo storyteller per costruire la propria storia.
Il componente chiave attorno al quale il modello si fonda è lo stato. Esso può essere assimilato a una sorta di “punto di salvataggio”: a partire dal salvataggio iniziale (ciò che indichiamo con il termine storia), essa va evolvendosi ad ogni iterazione, lasciando l’utente proseguire nel gioco. L’entità che implementa il concetto di stato prende appunto nome di State.
A un livello più pratico, i vari componenti dello State sono propedeutici alla messa in atto della pipeline, permettendo la trasformazione di comandi sotto forma di stringhe testuali in comandi comprensibili dal modello (Statement), applicabili a loro volta sullo State, modificandolo. Lo State deve contenere indicazioni riguardo ai seguenti componenti (astraendo dalle strutture dati utilizzate):
l’insieme di
Actione deiVerbad essi associati. Questi permettono di mappare i verbi che lo user include all’interno dei comandi testuali, a delle entità comprensibili dal modello. Una volta definiti, non dovrebbero essere modificabili durante il gioco;l’insieme di
Itemdisponibili: perItemsi intende un qualunque componente con il quale il player può interagire durante il gioco. Essi devono essere definiti nella fase iniziale del gioco, anche se possono non essere inizialmente visibili. L’unico vincolo è quindi quello di non poterne generare di nuovi a runtime;L’insieme di
Room: unaRoomrappresenta una porzione geografica della mappa del gioco. Il player durante il gioco deve avere la possibilità di muoversi tra leRoom. La stanza può concettualmente contenere dinamicamente degliItema runtime; deve contenere un’indicazione riguardo alleRoomlimitrofe (direttamente raggiungibili dallaRoomcorrente, con un passo in direzione di un punto cardinale);Il
Ground: esso rappresenta un’entità in grado di gestire i verbi intransitivi nella modifica dello stato;Varie altre indicazioni rappresentative dello stato, potenzialmente espandibili.
Porre in atto un’implementazione per queste entità non è stato banale. Le principali problematiche sono legate a:
Dipendenze incrociate: lo
Statecontiene concettualmente degliItem, ma all’atto pratico anche gliItemdevono venire a conoscenza delloState. Stesso ragionamento vale per leRoom;Evoluzione dello stato: lo
Stateè un’entità immutabile; per poterla aggiornare, è necessario crearne una copia modificata, e per far ciò si deve conoscere il tipo concreto alla base di ogni entità. A causa delle dipendenze incrociate, ogni entità deve conoscere il tipo concreto di ognuna.
La miglior soluzione a cui siamo giunti è stata quella di definire le interfacce base di State, Item e Room all’interno di un trait Model. Sulla base di ciò sono state poi definite delle Lens per rendere possibile la modifica delle singole entità.
5.4.1 Aggiornamento dello stato e behavior-based model
Un altro importante sfida nella definizione del modello riguarda la messa in atto di un meccanismo tale da consentire allo stato di “reagire” ai comandi utente.
Nel capitolo precedente si è utilizzato il termine Statement per indicare l’output della fase di resolving della pipeline. Tale output rappresenta un comando interpretabile dal modello. Ciò significa che al termine della fase di risoluzione, si ha conoscenza riguardo a quali sono gli Item e le Action coinvolti nel comando.
La fase d’interpretazione della pipeline è quella predisposta all’individuazione delle modifiche da applicare allo stato. L’output della fase è una Reaction, ovvero un’entità comprendente funzioni in grado di applicare allo stato le modifiche necessarie, e un’insieme di informazioni da mostrare in output all’utente (concetto approfondito nella sezione sec. 5.4.2). La fase viene posta in atto come segue:
nel caso di comandi intransitivi (
Statementcomposto da una solaAction), l’Actionviene applicata direttamente a un’entità interna allo stato, responsabile di gestire comportamenti intransitivi. Tale entità prende il nome diGround, e deve esporre un metodoGround::use(action), con output la rispettivaReaction;nel caso di comandi transitivi e ditransitivi (
Statementcomposto da unaAction, unItemsottoposto a tale azione, e un eventualeItemindirettamente coinvolto), l’Actionviene applicata all’Itemoggetto dell’azione, passandogli un’eventuale indicazione riguardo all’item indirettamente coinvolto. Di conseguenza anche gliItemdevono esporre un metodoItem::use(azione, itemIndiretto), e ritornare la rispettivaReaction.
Alla luce di ciò, si è reso necessario un meccanismo flessibile, modulare, facilmente utilizzabile dallo storyteller, che permettesse di definire il comportamento della funzione ::use.
L’idea a cui si è giunti si basa sul concetto di behavior. Un behavior è proprietà, caratteristica degli Item e dei Ground, tale da permettere l’integrazione modulare, all’interno di un Item (o un Ground), della logica per la gestione di determinate combinazioni Action-Item.
Ad esempio, integrando a un item apple il comportamento Takeable, diventa possibile durante il gioco prendere la mela (comando take the apple), restituendo la Reaction corrispondente.
La potenza di tale meccanismo risiede nella sua estendibilità: ogni behavior può facilmente essere esteso, integrando ulteriori combinazioni all’interno degli stessi, o sovrascrivendo eventuali comportamenti predefiniti.
All’atto pratico, ciò è stato reso possibile definendo un ulteriore trait che estende il Model di base:
estendendo il concetto di
ItemeGround, fornendo ad essi la possibilità di integrare loro dei behavior (BehaviorBasedItemeBehaviorBasedGround);fornendo un’implementazione flessibile del concetto di behavior, (
GroundBehavioreItemBehavior);fornendo un costrutto in grado di definire combinazioni
Action-Item(GroundTriggereItemTrigger).
5.4.2 Reaction
Nelle sezioni precedenti si è spesso fatto riferimento al termine Reaction, come una funzione in grado di modificare lo stato e di tener traccia dell’output da mostrare all’utente. Nella pratica, ciò si concretizza in una funzione State => (State, Seq[Message]), che, preso lo stato attuale, ne produce una nuova istanza e una sequenza di messaggi. Permette quindi sia di rappresentare un cambiamento nello stato della partita, che la notifica di avvenuto evento. Possibili implementazioni potrebbero essere takeTheItem(i: Item), move(direction: Dir), ecc.
È un concetto chiave utilizzato all’interno del Reducer, componente che agisce in coda alla Pipeline dopo l’Interpreter, e che si occupa di restituire lo stato aggiornato insieme alle notifiche sugli effetti prodotti dal comando sulla partita.
Il concetto di Reaction è stato ampliato inizialmente con un metodo ::combine(), che consente di combinarne una coppia, in modo che lo stato risultante della prima sia passato come argomento della seconda e che i messaggi siano concatenati. Successivamente sono stati introdotti altri metodi che semplificano un approccio funzionale, il più importante dei quali è flatMap, che abilita la creazione e concatenazione di più reazioni utilizzando il costrutto for comprehension di Scala.
5.4.3 I Message e il Pusher
Si è fatto riferimento, nelle sezioni precedenti, alla necessità di avere un output, da poter mostrare all’utente, al termine dell’esecuzione della pipeline. Come scelta progettuale, si è deciso di separare l’output vero e proprio, da delle notifiche di avvenuto evento, che fanno scaturire lo stesso. Ciò permette di avere una separazione più netta dei concetti, supportando potenzialmente diverse tipologie di output (non soltanto testuale).
La pipeline, oltre a fornire come output lo stato aggiornato, restituisce infatti una sequenza di notifiche. Esempi di notifiche potrebbero essere l’apertura di una porta, l’uccisione di un avversario, l’aver mangiato una mela, ecc. Nella nostra implementazione, tali notifiche prendono il nome di Message.
Al di fuori della pipeline è quindi necessario un componente in grado di associare ad ogni Message, il corrispondente output, facilmente personalizzabile dallo storyteller. A tale scopo, nella nostra implementazione è presente il componente Pusher. Esso viene implementato come un’abstract class che permette di definire una mappatura tra dei Message in input con un output di tipo generico. StringPusher è un’abstract class che estende poi il Pusher, supportando output di tipo String.
Il Pusher è facilmente personalizzabile dall’utente. Per essere utilizzato, deve essere esteso, andandone a implementare i ::messageTriggers. Un MessageTriggers altro non è che una PartialFunction, che permette di definire le varie corrispondenze tra Message e output.
5.4.4 Commons
Il package model contiene, tra gli altri, anche delle implementazioni “pronte all’uso” di vari Item, Action, Verb, Reaction, Ground e Pusher, di uso comune nell’implementazione di storie. Questi sono contenuti all’interno del package commons. È possibile integrare questi ultimi nel trait BehaviorBasedModel mixandoli all’interno dello stesso: si è infatti strutturato il package in maniera tale da contenere le implementazioni in differenti trait. Nel progetto, in generale, i trait marcati con il suffisso Ext possono essere mixati al model principale; quelli che iniziano con il prefisso C sono inoltre dei trait facenti parte di commons.
5.5 CLI
Questo modulo rappresenta di fatto un’implementazione che fa uso dei concetti presenti in ApplicationStructure. Dentro cli viene definito un game loop utilizzando ZIO come strumento per la gestione delle interazioni con la console, che in questo modo risultano essere type safe.
L’applicazione viene implementata tramite uno schema REPL (Read-Eval-Print-Loop), che consente ad ogni iterazione di inserire un comando che viene interpretato dal gioco e a cui corrisponde un output. Nello specifico i passi principali da eseguire sono i seguenti:
Lettura della frase inserita: questa parte viene gestita attraverso ZIO, il quale si occupa della lettura dalla console in maniera type safe.
Messa in azione della pipeline: la frase letta dalla console viene inoltrata alla
Pipeline. Questa si occupa di elaborare il risultato in forma:- messaggio di errore (qualora non fosse andato a buon fine);
- nuovo stato aggiornato;
- sequenza di messaggi da restituire in uscita.
Creazione del messaggio in output: in base al risultato restituito dalla
Pipeline, viene creato il messaggio da mostrare sulla console. In particolare, se si è verificato un errore, viene ritornato un avviso che lo descrive, altrimenti viene restituita la sequenza di messaggi. In quest’ultimo caso viene anche aggiornato lo stato.Stampa del messaggio in uscita: viene stampato su console il messaggio o la sequenza di messaggi calcolati nel punto 3.
Controllo di terminazione: infine viene controllato se il gioco è terminato, e qualora non fosse così, viene richiamato ricorsivamente questo schema, ritornando al punto 1 precedente.
Gli errori che vengono emessi dalla Pipeline sono stati trasformati in messaggi, in quanto come nelle shell dei comandi, i refusi (intesi come ad esempio “input non compreso” o “operazione non possibile”) sono considerati come parte integrante del sistema.
6 Implementazione
In questo progetto sono diversi i temi implementativi salienti riscontrati. Di seguito sono descritti i punti principali, divisi in base all’autore o agli autori che li hanno sviluppati.
6.1 Aspetti trattati in comune
Alcuni task relativi allo sviluppo del software hanno richiesto l’attenzione di tutti i membri del team, in sedute comuni di programmazione e di scambio d’idee. Tra questi:
- task relativi a sezioni strategiche del software;
- task particolarmente complessi, tali da richiedere competenze possedute da più sotto-team;
- task relativi allo sviluppo di sezioni “cuscinetto” tra moduli differenti, tali da richiedere conoscenze riguardo a strutture sviluppate separatamente da sotto-team differenti.
È possibile individuare i seguenti task con queste caratteristiche:
- Lo sviluppo degli esempi;
- Il lavoro delle primissime iterazioni, nelle quali è stata posta la base di progetto, e la suddivisione in più sotto-progetti Gradle;
- Lo sviluppo delle strutture alla base del model;
- Lo sviluppo delle strutture alla base della pipeline.
6.2 Aspetti trattati in sotto-team
Allo scopo di rendere il lavoro parallelo e flessibile, gran parte del lavoro è stato spartito tra due sotto-team, con responsabilità legate a parti di progetto differenti.
6.2.1 Team 1
Il team 1 è composto dai membri Riccardo Maldini, Jacopo Corina, Thomas Angelini. Sono stati trattati specifici aspetti del Core, legati in generale alla definizione del modello. Nello specifico:
sviluppo di buona parte del modello, e del sotto-modulo
commons, corrispondente a grandi linee al packagemodel;sviluppo di componenti interni al modulo
pipeline, qualiresolver,interpreterereducer.
6.2.2 Team 2
Il team 2 è composto dai membri Filippo Nardini, Francesco Gorini. Sono stati trattati specifici aspetti del core, legati in generale alla definizione dell’engine di gioco, e alla struttra di base del modulo cli Nello specifico:
Package
core:dictionarycon tutti i suoi elementi;pipelinein particolare gli elementiLexereParser;applicationcon tutti i suoi elementi;parsingcon tutti i suoi elementi.
Package
cli.
Occorre sottolineare che i concetti son stati sviluppati totalmente in “pair programming”. Tuttavia, successivamente, vengono descritti quali sono le parti di cui personalmente un membro del team è responsabile.
6.3 Responsabilità personali
Personalmente ogni elemento del team ha svolto dei task specifici, legati ai task principali del team, ma non esclusivamente:
Thomas Angelini: Il membro ha gestito lo sviluppo del sotto-modulo
commonsall’interno dimodel.behaviorBased, ha redatto una buona parte di ScalaDoc e spesso coinvolto in molti test. La maggior parte del lavoro è stato svolto in concomitanza con gli altri membri del team.Jacopo Corina: Oltre alle parti svolte assieme agli altri membri, il membro ha contribuito a creare la struttura base del meccanismo dei behavior e alla relativa integrazione, per poi ulteriormente svilupparla assieme agli altri membri. In particolare ha contribuito alla creazione dei vari item di gioco con behavior annessi e alla parziale implementazione delle componenti
Resolver,Interpreter,Reducer.Inoltre, si è dedicato alla predisposizione iniziale ed all’ottimizzazione dei workflow CI ed alla esplorazione dei possibili metodi di release per il codice sorgente, gli eseguibili degli esempi, la generazione dei report e la parziale implementazione essi
Riccardo Maldini: Il membro ha curato in particolare lo sviluppo delle entità di base del model, e parte della sua implementazione principale basata su behavior. Gran parte del lavoro riguardo questo aspetto è stato ad ogni modo portato a termine nel contesto del team 1.
Oltre a ciò, il membro è responsabile dello sviluppo di vari task minori:
- Ruolo di Scrum Master, e in generale di coordinatore del backlog;
- Sviluppo di parte dei workflow CI/QA,
- predisposizione della prima base progettuale Gradle basata su convention plugin e submodule
- Sviluppo di parte dei workflow di release.
Filippo Nardini: il membro del team si è preoccupato di curare particolarmente le parti riguardanti il sottoprogetto cli, soprattutto per quanto concerne l’utilizzo di ZIO. In aggiunta si è occupato anche della parte di
dictonary. Infine, per quanto riguarda il linguaggio Prolog, è responsabile della parte comprendente la modellazione della grammatica attraverso algebraic-data type e di tutte le altre parti presenti nel packagescalog.Francesco Gorini: il membro ha contribuito alla stesura dei primi due componenti del package
pipeline, ovvero Lexer e Parser. In aggiunta è responsabile di quanto è stato creato dentro il packageapplication, comprendente tutte le parti necessarie per fornire una struttura di base implementabile. Inoltre il membro si è occupato della parte riguardante il motore Prolog, l’interfacciamento con la libreria tuProlog e tutto ciò che comprende il packageengine.
6.4 Dettagli implementativi
I dettagli implementativi riguardo i principali aspetti trattati sono esposti quì di seguito.
6.4.1 Model
Riguardo alla definizione del modello, vanno sottolineate le seguenti scelte implementative:
A causa delle dipendenze circolari tra
Room,ItemeState, tali entità sono state definite all’interno di una abstract class comune, denominatoModel. Tale scelta implica la necessità, per tutte le funzioni che hanno bisogno di uno dei tipi concreti forniti dal modello, di conoscere l’istanza del modello stesso, influenzando profondamente la struttura di molti componenti di progetto, che vanno così a realizzare dei dependent types:Tale scelta ha inoltre influenzato il resto dell’implementazione, determinando la necessità di espandere l’implementazione tramite una gerarchia che parte dal
Model.L’implementazione del
Modelbasata sul meccanismo dei behavior viene integrata tramite l’utilizzo dell’abstract classBehaviorBasedModel. All’interno di questa vengono definiti i concetti diBehaviorBasedItem,ItemBehavior,BehaviorBasedGround,GroundBehavior. Le “combinazioni” diActioneItemin grado di far scattare comportamenti vengono definiti in deiSetinterni agli stessi, contenenti deiGroundTriggerseItemTriggers. Questi non sono altro che wrapper perPartialFunction[(Action, State), Reaction]ePartialFunction[(Action, Option[Item], State), Reaction], sulla base dei quali vengono implementati i metodiBehaviorBasedGround::use()eBehaviorBasedItem::use(), combinando tra loro tramite::lift()tutti i triggers propri di un certo behavior.Internamente,
RoomeItemsono completamente descritti dal proprio riferimento (RoomRefeItemRef); comportamento implementato effettuando l’override dei metodi::equals()e::hashCode()degli stessi, abilitando il confronto sulla base appunto dei soli ref, anziché sull’hashcode dell’intero oggetto. Ciò permette di comparare tra di loroRoom(oItem) che, pur rappresentando lo stesso concetto, hanno delle differenze legate all’implementazione, rendendo al contempo più agevoli i test.A livello implementativo, le
Roomnon contengono al loro interno gliItemconcreti presenti al loro interno, ma i soli riferimenti alle stesse. Per restituire gliItemconcreti, laRoomdeve risolverli, prendendo in input loState, il quale contiene laMapche memorizza gliItemeffettivi. Ciò evita ad esempio inconsistenze tra i dati.Le case class che implementano i
BehaviorBasedItemsono intese come delle categorie di oggetti (ad esempio: la categoria di oggettiKeydenota l’insieme di oggetti che potenzialmente potrebbero aprire un item di tipoDoor). In fase di costruzione degli stessi, gliItemBehaviorche caratterizzano gli item vengono passati come delle higher order functionI => ItemBehavior, eseguite una volta costruito l’oggetto. Questo in quanto gliItemBehaviornecessitano di un subject, ovvero di un riferimento agli item che li hanno generati.
6.4.2 Commons
Commons contiene una serie di componenti pre-implementati e utility, pensati per facilitare allo storyteller lo sviluppo della propria storia.
È possibile importare tutti i componenti comuni semplicemente mixando all’interno di un BehaviorBasedModel il trait CommonsExt, che fornisce tutti gli elementi del package stesso.
Tale package è formato da alcuni sotto-package, seguono un pattern comune. All’interno di ogni sotto-package, viene reso disponibile un trait mixabile nel BehaviorBasedModel. Questo permette di integrare direttamente al model tutti i trait contenuti nel sotto-package impl.
Questo meccanismo si è reso necessario in quanto, per implementare le varie funzionalità, è spesso richiesto di accedere al tipo concreto di Item, Room, Ground. Tali tipi, a causa dell’utilizzo dei path dependent type, può essere acceduto soltanto a partite dal Model originario.
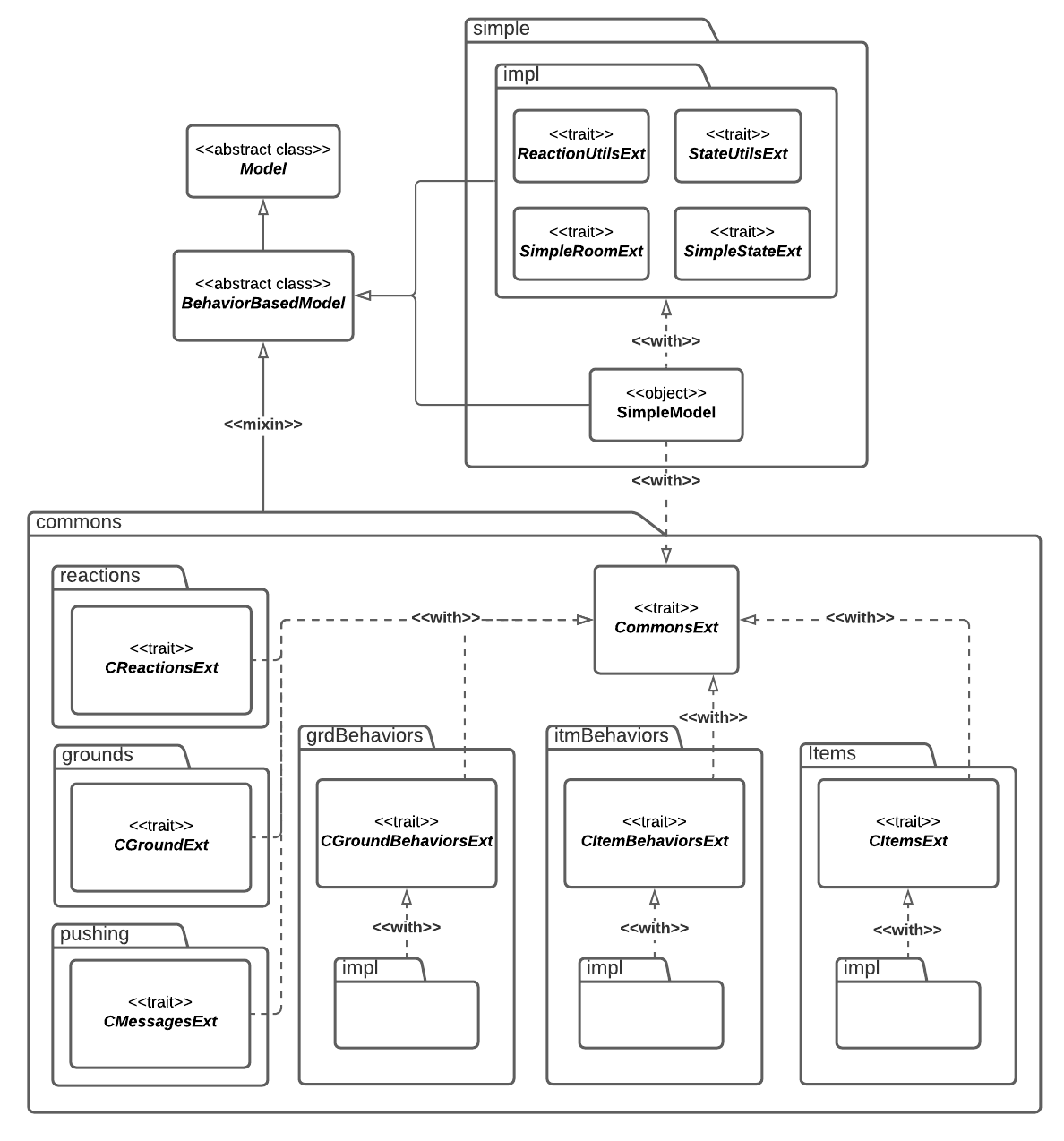
La struttura di Commons può risultare complessa nella sua comprensione. Si riporta il diagramma dele classi in fig. 6.1 per facilitarne la comprensione. Scendendo nel dettaglio, i package in esso contenuti sono i seguenti:
actioning, contente implementazioni comuni di
ActioneVerb;groundBehavior, contenente dei
Behaviorche possono essere integrati all’interno di unGround, ovvero tutti i comportamenti accessibili tramite verbi intransitivi. Tra questi, la possibilità di ispezionare laRoomcorrente (inspect), navigare tra differenti stanze (go North)grounds, contenente implementazioni standard del costrutto
Ground. Contiene, ad esempio, un’implementazione diGroundtale da includere iGroundBehaviorcitati in precedenza;itemBehavior, contenente dei
Behaviorche possono essere integrati all’interno di unItem, ovvero tutti i comportamenti accessibli tramite verbi transitivi e ditransitivi. Tra questi, la possibilità di afferrare unItem(take the sword), aprire unItem(open the door with the key), o mangiarlo (eat the apple).items, contenente delle implementazioni comuni di
BehaviorBasedItem. Ad esempio, unChestè un particolareItemche riversa nellaRoomcorrente degliItemuna volta aperto, unFoodè unItemmangiabile, e così via.pushing, contenente alcune implementazioni di
Messagee una per ilPusher, comunemente utilizzate, e sfruttate ampiamente nell’implementazione dei package precedenti.Pusherriconosce tutti iMessagedel packagepushinge produce risposte sotto forma di stringa. Tali messaggi sono già gestiti dalPusher, ma la risposta può anche essere personalizzata dallo storyteller all’interno della storia;reactions, contenente delle
Reactioncomunemente utilizzate. Assume particolere rilevanza in quanto al suo interno sono presenti delle funzioni che “wrappano” delle Lens che agiscono sulloState, permettendo di utilizzare più facilmente le stesse.
6.4.3 Resolver
Dato il risultato del Parser (un AST), il Resolver associa ad ogni suo elemento un significato all’interno del sistema, producendo in output uno Statement, ossia un comando comprensibile dal modello;
Per l’implementazione, si sfrutta una classe astratta AbstractSyntaxTreeResolver, la quale fornisce una gestione completa delle possibili casistiche ottenibili dal risultato della parte di parsing ParsingResult: l’ abstract syntax tree contenuto nel risultato viene distinto mediante pattern matching sulle classi AbstractSyntaxTree.Intransitive, AbstractSyntaxTree.Transitive e AbstractSyntaxTree.Ditransitive. In ultimo caso, se la classe non fosse di una delle ammesse, verrebbe restituita una stringa, contenente potenzialmente il messaggio di errore, ed essa sarà propagata come risultato alternativo del ciclo di pipeline. Nei casi ammessi, vengono estratti gli attributi presenti e si verifica se essi sono presenti tra le actions e gli items ammessi, tornando in caso affermativo uno Statement di tipo corrispondente a quello matchato, che sarà wrappato da un oggetto ResolverResult. Se vi fossero mancate corrispondenze con actions o items, al pari della casistica di errore precedente, verrebbe restituita una stringa di errore.
La classe Resolver fornisce una possibile implementazione di AbstractSyntaxTreeResolver, implementando in ::actions il controllo sulla presenza della action passata nello stato, e in ::items il controllo sulla presenza dell’item passato nello scope di gioco (insieme degli oggetti presenti nella bag o nella location del player). L’implementazione si basa su un criterio di confronto tra ItemDescription dell’ oggetto con quella degli altri nello scope: per poter avere un match il nome deve essere il medesimo, ed eventuali aggettivi dell’oggetto ricercato devono essere un sottoinsieme dell’altro oggetto preso in considerazione. Ad esempio, se nello scope fosse presente una sola mela (senza aggettivi) e si cercasse una mela verde, non si otterrebbe alcuna corrispondenza. Se fosse presente una mela verde e si cercasse una mela rossa, non si avrebbe alcuna corrispondenza, mentre se fossero presenti entrambe le mele con aggettivi e se ne cercasse una senza alcuno vi sarebbero corrispondenze multiple quindi si renderebbe necessaria una disambiguazione.
6.4.4 Interpreter
Dato il risultato del Resolver, l’Interpreter si verifica che sia possibile applicare lo Statement sullo stato corrente del gioco. Quando possibile, viene generata in output una Reaction, ossia una funzione contenente le eventuali modifiche da applicare sullo stesso.
Utilizzando ResolverResult ottenuto da Resolver, la classe Interpreter si occupa di eseguire un pattern matching sullo Statement contenuto in esso, distinguendolo in base alla classe Intransitive, Transitive, Ditransitive.
In assenza di match, viene restituito, come nel caso riportato in Resolver, una stringa di errore.
Nel caso Intransitive, il metodo ::use è invocato su un oggetto di tipo Ground, che rappresenta un sorta di oggetto “virtuale” ed è contenuto all’ interno dello stato. Nei casi Transitive e Ditransitive è stata utilizzata una classe di utility chiamata RefToItem, che consiste in un extractor da utilizzare per ottenere l’ Item partendo da ItemRef, reperendolo da un dato dizionario degli elementi, in questo caso quello contenuto all’ interno dello stato. In questi ultimi 3 casi, viene restituita una Reaction wrappata all’ interno di un oggetto InterpreterResult.
6.4.5 Reducer
Data la Reaction ottenuta al termine del passo precedente, il Reducer provvede ad applicarla allo State del gioco, aggiornandolo e generando eventuali messaggi utili per l’interazione con lo user.
Utilizzando InterpreterResult ottenuto da Interpreter, prendendo la Reaction contenuta, essa viene applicata sullo stato. Il risultato, nella implementazione realizzata, consiste in una tupla contenente 2 elementi:
- stato aggiornato a seguito dell’ applicazione della
Reaction - messaggi per lo user, generati a seguito dell’ applicazione della
Reaction
Questa tupla è wrappata all’ interno della classe ReducerResult.
6.4.6 Generators
Le type class Generator e GeneratorK che si trovano all’interno di questo modulo sono state realizzate utilizzando le type class offerte da Cats. L’implementazione di Generator[A, B] risulta essere un banale wrapper di una funzione A => B, mentre l’implementazione di GeneratorK[F[_], A, B] richiede che siano state definite istanze per le seguenti type class:
Generator[A, B]:essere in grado di generare da ogni valore a: A un output b: B;Functor[F]eFoldable[F]:in quanto sono necessarie le funzioni map e fold, per trasformare all’interno ed infine estrarre un valore b: B a partire dal contestoF[_];Monoid[B]:in quanto è necessaria un’operazione binaria associativa e un valore empty per effettuare l’operazione di fold.
6.4.7 Dictionary
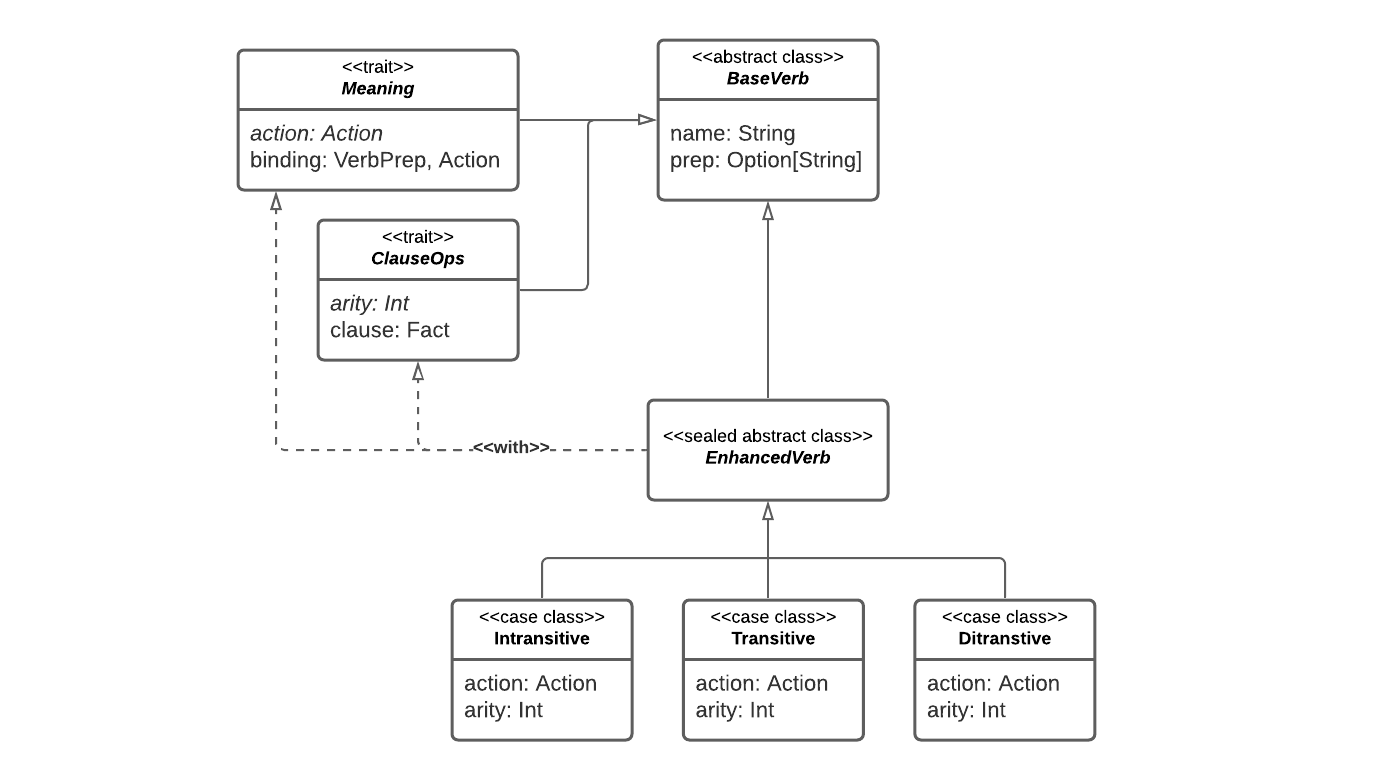
Contiene i costrutti, realizzati tramite algebraic data types, che consentono la dichiarazione di verbi, utilizzati in fase di scrittura di una storia da parte dello storyteller. La sua struttura viene riportata graficamente in fig. 6.2. A partire da un verbo deve essere possibile generare le seguenti informazioni:
- una regola Prolog, che descrive la grammatica del verbo;
- una tupla
(Verb, Preposition) -> Action(oVerb -> Action), che collega l’uso del verbo al suo significato.
Contiene inoltre una funzione in grado di generare, a partire dal dizionario di una storia e dalla grammatica di base, una teoria Prolog utilizzata per inizializzare un Engine. Per fare ciò utilizza due istanze di GeneratorK[List, Verb, Program] e GeneratorK[List, Item, Program], in grado di generare per ogni classe di elemento del dizionario un programma Prolog valido. Infine questi programmi vengono concatenati tra di loro e alla grammatica di base.
6.4.8 Scalog
Questo package contiene le strutture necessarie per la modellazione di espressioni Prolog. La realizzazione della gerarchia è avvenuta tramite algebraic data types e ha origine nel tipo CodeGen, una struttura in grado di generare un’espressione Prolog sotto forma di stringa, che in seguito si suddivide in Clause e Term, che rappresentano rispettivamente una clausola e un termine (fig. 6.3).
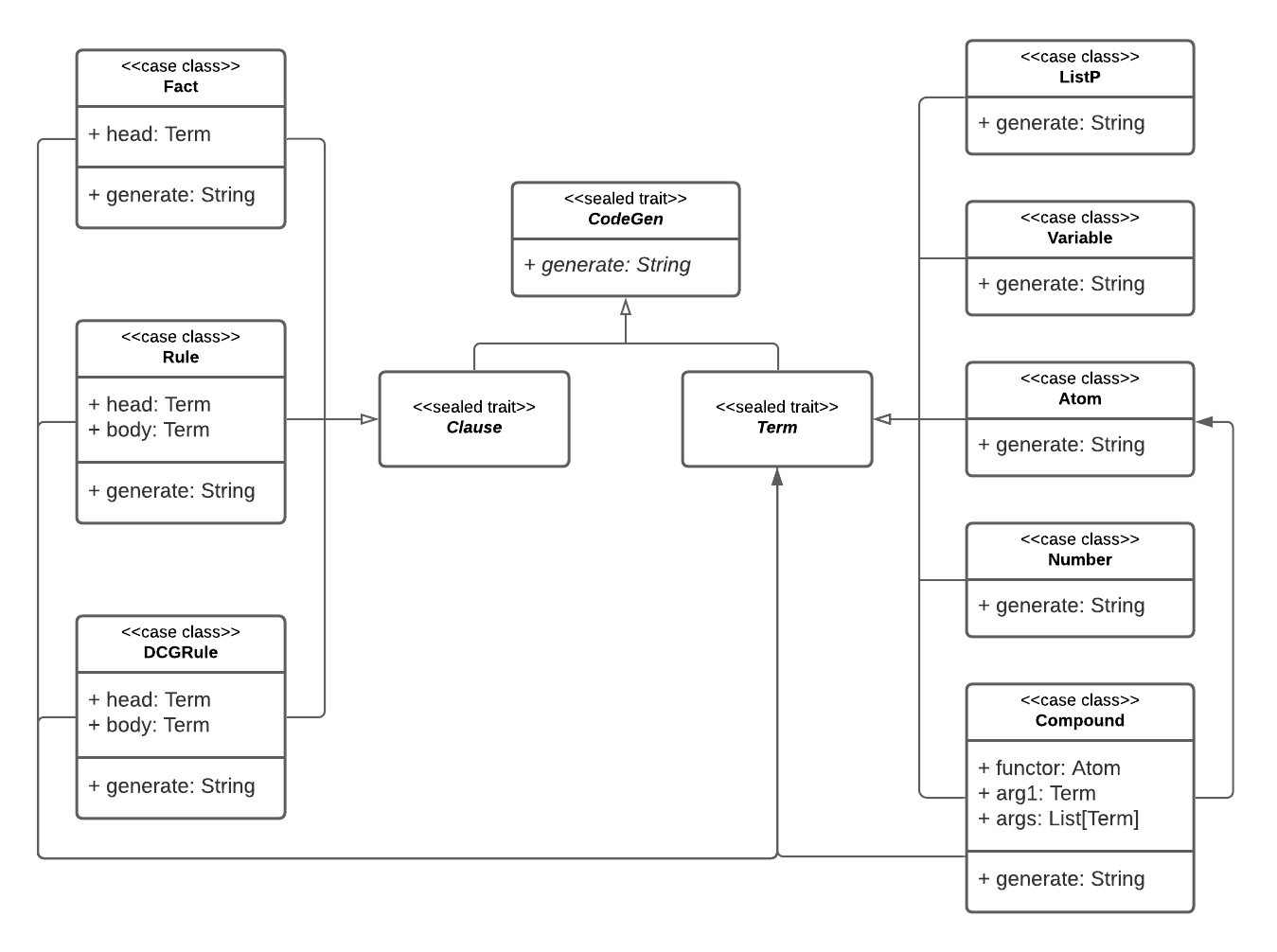
I tipi di clausola che sono stati modellati sono:
Fact, che rappresenta un semplice fatto senza corpo;Rule, che rappresenta una clausola di Horn con testa e corpo;DCGRule, che rappresenta una clausola espressa in forma DCG.
I tipi di termine che sono stati modellati sono:
Atom, che rappresenta un atomo;Number, che rappresenta un numero (è stato modellato il solo uso di numeri interi);Variable, che rappresenta una variabile;Compound, che rappresenta un termine composto da funtore e argomenti;ListP, che rappresenta una lista.
Inoltre è stato implementato un piccolo DSL, che consente la creazione di clausole e termini tramite una sintassi molto simile a quella di Prolog (esempio in lst. 6.1).
Listing 6.1: Esempio di utilizzo del DSL per la creazione di una regola DCG.
import io.github.scalaquest.core.parsing.scalog.dsl._
import io.github.scalaquest.core.parsing.scalog._
val hello = CompoundBuilder("hello").constructor
val X = Variable("X")
(hello(X) --> ListP("hello", X)).generate
// val res0: String = "hello(X) --> [hello,X]."L’uso di algebraic data types rende molto semplice il pattern matching, rendendo l’uso di queste strutture molto comodo come formato di scambio dati tra diversi componenti, per esempio tra PrologParser e Engine. A tal fine sono stati introdotti ulteriori metodi per rendere il pattern matching ancora più espressivo (esempio in lst. 6.2).
Listing 6.2: Esempio di utilizzo del DSL per il pattern matching di una struttura.
val nickname = CompoundBuilder("nickname").extractor.toStrings
val record = Compound("nickname", "robert", List("bob"))
record.generate
// val res0: String = "nickname(robert, bob)"
record match {
case nickname(_) => "wrong usage of nickname/2"
case nickname(_, _, _) => "wrong usage of nickname/2"
case nickname(full, nick) => s"${nick} stands for ${full}"
case _ => "you didn't say hello to anyone"
}
// val res1: String = "bob stands for robert"6.4.9 Struttura di default dell’applicazione
All’interno del package application, tra i dettagli implementativi più interessanti vi è l’utilizzo del pattern “Template Method” all’interno di DefaultPipelineProvider (fig. 6.5) per creare la pipeline di default. In particolare è interessante notare che definendo solamente una teoria Prolog, sia possibile fruire di una pipeline pronta all’uso.
6.4.10 Parser
Nell’implementazione di Parser viene utilizzato nuovamente il pattern “Template Method”, con il notevole beneficio di poter sviluppare completamente questa parte della pipeline senza dover necessariamente conoscere quale motore Prolog venisse implementato. Per questo motivo è stato possibile creare il package parser ben prima di sviluppare il modulo engine. Inoltre, in questo modo il codice risulta essere particolarmente scalabile e modulare, in quanto in maniera molto semplice ed in poco tempo, è possibile implementare un altro motore Prolog, che ad esempio lavora con SWI-Prolog.
6.4.11 Natural Language Processing in Prolog
La scelta per l’implementazione del natural language processing è ricaduta su Prolog, per via del particolare paradigma di programmazione che esso offre. Infatti la programmazione logica si presta molto bene allo sviluppo di analizzatori sintattici per il linguaggio naturale. È stata presa come riferimento la lingua inglese in quanto la forma dei verbi non varia con il variare del soggetto e per la vastità della letteratura sul NLP.
L’implementazione realizzata di parser del linguaggio naturale è basata su regole in forma definite clause grammar. Questa modalità di esprimere regole consente di definire una grammatica utilizzando dei costrutti molto espressivi.
Nell’implementazione della comunicazione tra il PrologParser e il motore Prolog si è scelto di utilizzare le frasi in forma imperativa, in quanto adatta ad impartire comandi al personaggio, e di rappresentare le strutture grammaticali nel seguente modo:
Listing 6.3: Esempio di risoluzione di query utilizzando la teoria prodotta per il NLP.
phrase(i(X), [take, the, key])
% yes. X / sentence(take/{}, you, key)
phrase(i(X), [open, the, door, with, the, key])
% yes. X / sentence(open/with, you, door, key).
phrase(i(X), [inspect])
% yes. X / sentence(inspect/{}, you)Listing 6.4: Esempio di parsing di un nome con aggettivi.
phrase(substantive(X), [the, big, red, key])
% yes. X / decorated(big, decorated(red, key))
phrase(substantive(X), [the, key])
% yes. X / key- il soggetto è sempre
you(poiché il modo del verbo è imperativo); - il verbo è rappresentato dal termine composto
/(<verbo>, <preposizione>), se non è presente nessuna preposizione è stato usato il termine{}(esempio in lst. 6.3); un verbo può essere in una di queste tre forme:- intransitivo
- transitivo
- ditransitivo
- il complemento può essere preceduto o seguito da una preposizione, questa verrà associata al verbo; inoltre può essere preceduto da un articolo;
- un nome può essere preceduto da un numero arbitrario di aggettivi, la rappresentazione utilizzata è stata
decorated(<aggettivo>, <nome>)(esempio in lst. 6.4).
Il motore TuProlog, che offre API fruibili da linguaggi basati sulla JVM, viene inizializzato con la necessaria teoria ed eseguito all’interno di un Engine, che esporrà il risultato della risoluzione di una query utilizzando i costrutti di scalog.
6.4.12 Engine Prolog
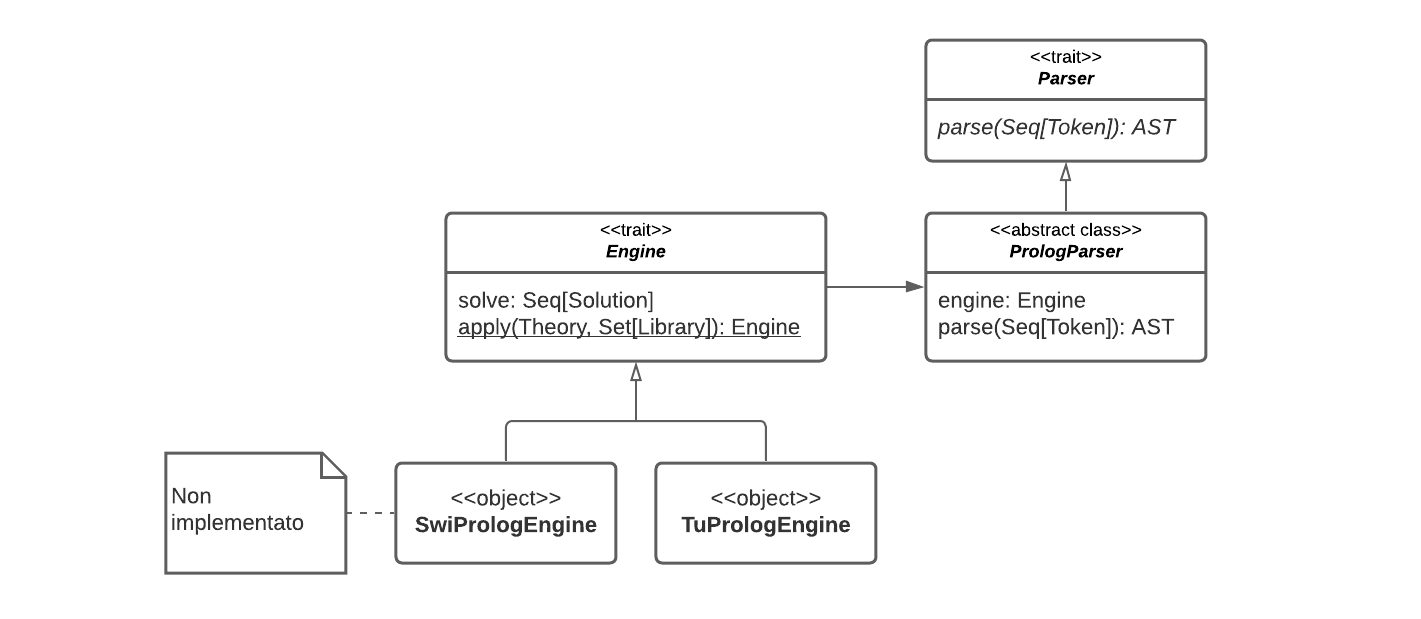
Questa soluzione utilizza il pattern “Adapter” per wrappare e permettere di utilizzare la libreria tuProlog all’interno del codice. Successivamente questa è stata arraggiata per modellare correttamente il nostro dominio; ad esempio è stata creata una interfaccia Engine la quale prevede di essere definita solamente attraverso Theory e Library. La struttura del package viene riportata in fig. 6.4.
Occorre sottolineare che in alcuni parti del codice, vengono gestite solo parzialmente le eccezioni che potrebbero essere sollevate nell’utilizzo del Prolog. Questa scelta è stata dettata da un duplice fattore: il codice altrimenti si sarebbe notevolmente “sporcato” con l’utilizzo di costrutti try/catch o di Option. Tuttavia, questa parte viene utilizzata e gestita interamente da i membri del team e quindi sappiamo come rispettare le interfacce, evitando di sollevare eccezioni.
6.4.13 CLI
Questo modulo si occupa di fornire dei costrutti per creare un’applicazione a linea di comando che consenta di interagire con un’istanza di gioco. La sua implementazione è basata sul framework ZIO, che consente di creare effetti (ovvero codice con side-effects) tramite costrutti type-safe, funzionali, quindi facilmente componibili e testabili. La struttura del modulo, e il modo in cui questo si interfaccia con il modulo Core e con ZIO, è riportata graficamente in fig. 6.5.
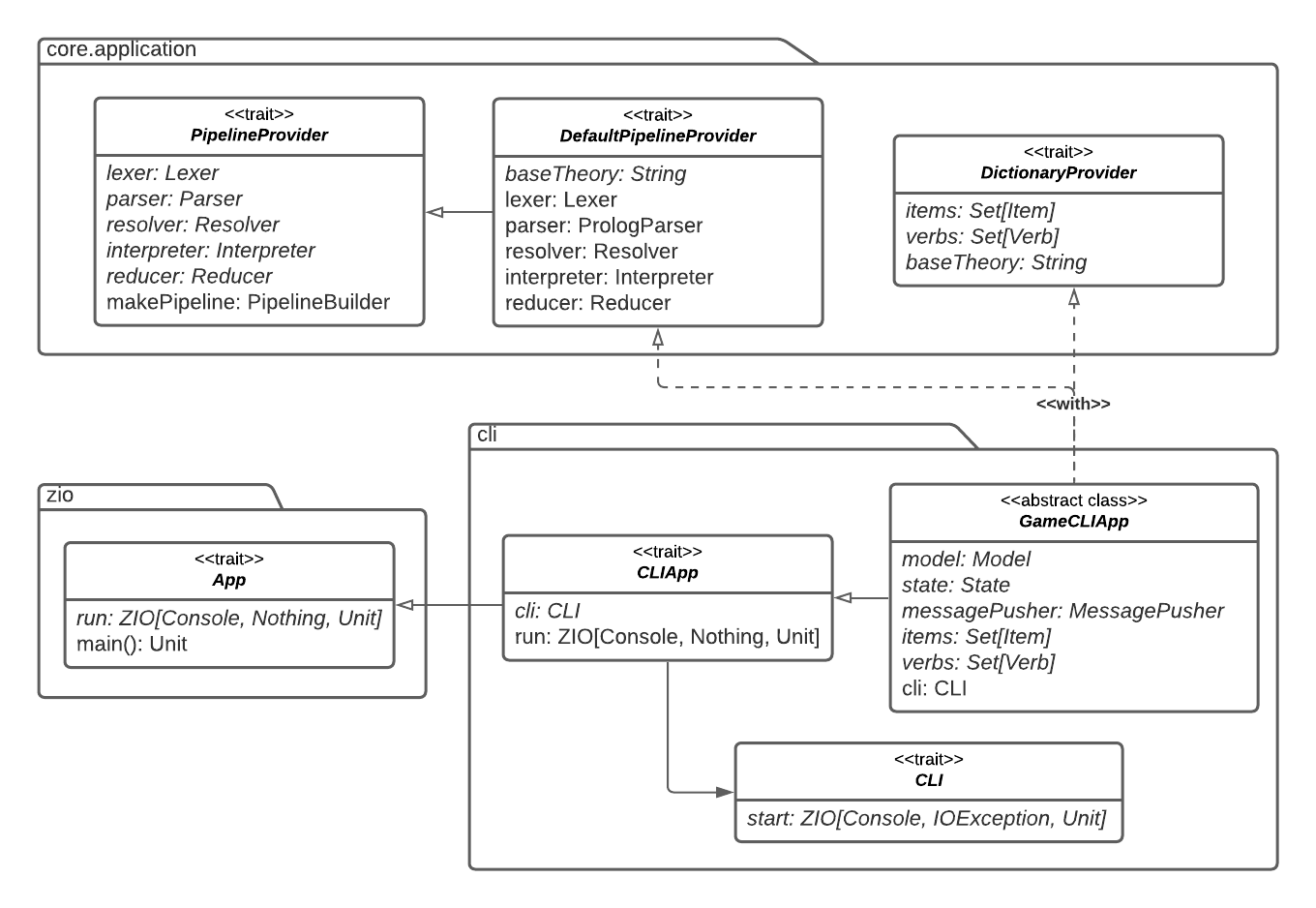
L’interfaccia principale è CLI, ovvero un wrapper per un effetto ZIO[Console, IOException, Unit], che può essere semplificato in Console => Either[IOException, Unit], ovvero una funzione che necessita di un’implementazione di Console e ritorna un’eccezione di tipo IO oppure un valore unit. ZIO offre un costrutto App che fornisce tramite un template method di realizzare facilmente un’applicazione eseguibile. Questo è stato esteso per creare GameCLIApp: una classe astratta, configurabile con istanze di Model, State, MessagePusher e gli elementi del dizionario tramite template method, realizza un applicazione eseguibile costruendo un’istanza di Game tramite una Pipeline di default.
All’interno del companion object di CLI è messo a disposizione un metodo che forniti i componenti necessari, (Model, State, MessagePusher e State) ne crea un’istanza di CLI. Questa al proprio interno realizza il pattern di esecuzione REPL introdotto in sec. 5.5. L’applicazione supporta, oltre all’input da indirizzare al gioco, anche l’uso di meta-comandi, ovvero comandi che non sono destinati all’istanza di gioco in esecuzione, bensì all’interprete dei comandi stesso. Questi includono operazioni come il salvataggio della partita corrente su un file o il caricamento di una partita da un file, se il Model utilizzato supporta queste operazioni.
7 Retrospettiva
Rispetto a progetti trattati in precedenza dai singoli membri del gruppo, in questo si è posta un’attenzione particolare alla metodologia e all’organizzazione di progetto. Si è cercato per quanto possibile di approcciare lo sviluppo con mentalità ingegneristica, pragmatica e strutturata.
7.1 Il backlog
Per il backlog di progetto è stato adottato GitHub Projects, un’alternativa a Trello che presenta una forte integrazione delle funzionalità di GitHub. Ragion per cui la quasi totalità dei task è associata a un issue o una pull request, tenendo traccia in maniera assolutamente trasparente del processo che ha portato alla risoluzione degli stessi. È possibile accedere alla board pubblica da questo link. La board è organizzata in diverse colonne:
Una colonna Backlog tiene traccia dei task che si è programmato di svolgere in futuro, con priorità inferiore rispetto allo Sprint corrente. Essa viene popolata in particolare durante lo Scrum meeting settimanale, nella definizione degli obiettivi di lungo termine;
Una colonna Backlog (current Sprint) tiene traccia dei task da svolgere nello Sprint corrente. Essa viene popolata principalmente durante lo Scrum meeting settimanale, permettendo una pianificazione dei task a maggiore priorità. Inoltre, nel caso in cui uno dei team riuscisse a terminare tutti i task ad esso assegnati durante lo Sprint, può aggiungerne degli altri, accingendo da quelli del backlog;
Una colonna In progress (current Sprint) tiene traccia dei task ai quali dei membri stanno attualmente lavorando;
Una colonna Done (current Sprint) tiene traccia dei task conclusi nello Sprint corrente. Dei trigger di automazione permettono di porre in automatico i task in questa colonna a seguito della chiusura di issue e al merge di pull request;
Una colonna Done tiene traccia dei task completati negli Sprint precedenti. La colonna viene popolata a seguito della terminazione dello Sprint, accingendo dai task terminati nello stesso.
Tale organizzazione non ha dato spazio ad equivoci, rendendo possibile monitorare in maniera continuativa l’operato del team, ed effettuare eventuali aggiustamenti in corso d’opera.
7.2 Organizzazione in Sprint
Il lavoro si è svolto in Sprint settimanali, intermezzati da meeting portati avanti principalmente nel fine settimana, durante la quale si sono svolte le fasi di Retrospective e Planning. Durante ogni meeting si è andato ad aggiornare un documento di overview, tale da tener traccia di ciò che è stato effettivamente fatto durante lo Sprint, completo di link alle pull request e agli issue ad essi collegati. Il documento è accessibile tra la documentazione di progetto, tra i documenti di appendice, consultabili via web o come LaTeX PDF.
Questo documento permette di ricostruire ciò che effettivamente è stato fatto ad ogni Sprint. Da questo si può anche notare come all’atto pratico alcuni task abbiano sforato il periodo di Sprint previsto, e come alcuni altri siano stati invece terminati in anticipo, dando spazio al team di occuparsi di task aggiuntivi. Ciò non ha però compromesso in maniera eccessiva lo svolgimento del progetto. Ritardi e anticipi sui tempi previsti sono stati gestiti in itinere, adattando incrementalmente l’organizzazione sulla base dei problemi riscontrati.
7.3 Processo di sviluppo
In generale, la fase implementativa è risultata essere particolarmente lineare ed efficace, comparata con altri progetti portati avanti in passato.
Particolare importanza è stata assunta in questo contesto anche dalle sessioni preliminari di knowledge crunching, nelle quali si son potuti mettere a nudo in anticipo buona parte degli aspetti architetturali, dei requsiti e delle problematiche legate al progetto.
In aggiunta, è risultata essenziale l’infrastruttura di automazione adottata. La messa in atto di workflow efficaci di Contiuous Integration, Quality Assurance, Linting del codice sorgente, combinati a sessioni di refactoring periodiche, ha permesso di individuare facilmente nel nascere e risolvere problematiche legate all’accumularsi di debito tecnico e alla qualità del codice.
7.4 Commenti finali
In conclusione, possiamo affermare che il progetto finale soddisfa in ogni parte i requisiti definiti in fase di analisi. Questo ha portato a grande soddisfazione da parte dei membri del team, in quanto raggiungere gli obiettivi prefissati a pieno non era considerato affatto scontato nelle fasi iniziali.
Il livello di qualità del codice è da considerarsi buona per la maggior parte delle sezioni, avendo raggiunto al contempo il livello di espressività inizialmente prefissato. Ciò si rispecchia nella semplicità (sia di utilizzo delle API, sia per la presenza di elementi di base) con cui un utente “story teller” è in grado di creare storie più o meno complesse.
Come membri del team ci teniamo inoltre ad aggiungere che nessuno di noi aveva in precedenza lavorato ad un progetto con un’organizzazione e una metodologia strutturata. Due membri del team provengono poi da una triennale differente dal percorso degli altri (Riccardo Maldini e Francesco Gorini, UniUrb), la quale proponeva un approccio ai progetti ben più approssimativo. Una sfida che si è accettata di buon grado, coscienti delle potenzialità dei singoli.
È necessario far presente che alcuni problemi sono incorsi tra la release 0.3.1 e 0.4.0, frangente nel quale, a seguito di un errore nelle politiche di commit, si è dovuto agire tramite rebase per preservare la repository. La storia tra questi due tag risulta quindi non perfettamente lineare.↩︎
- 1 Introduzione
- 2 Processo di sviluppo adottato
- 3 Requisiti
- 4 Design architetturale
- 5 Design di dettaglio
- 6 Implementazione
- 7 Retrospettiva